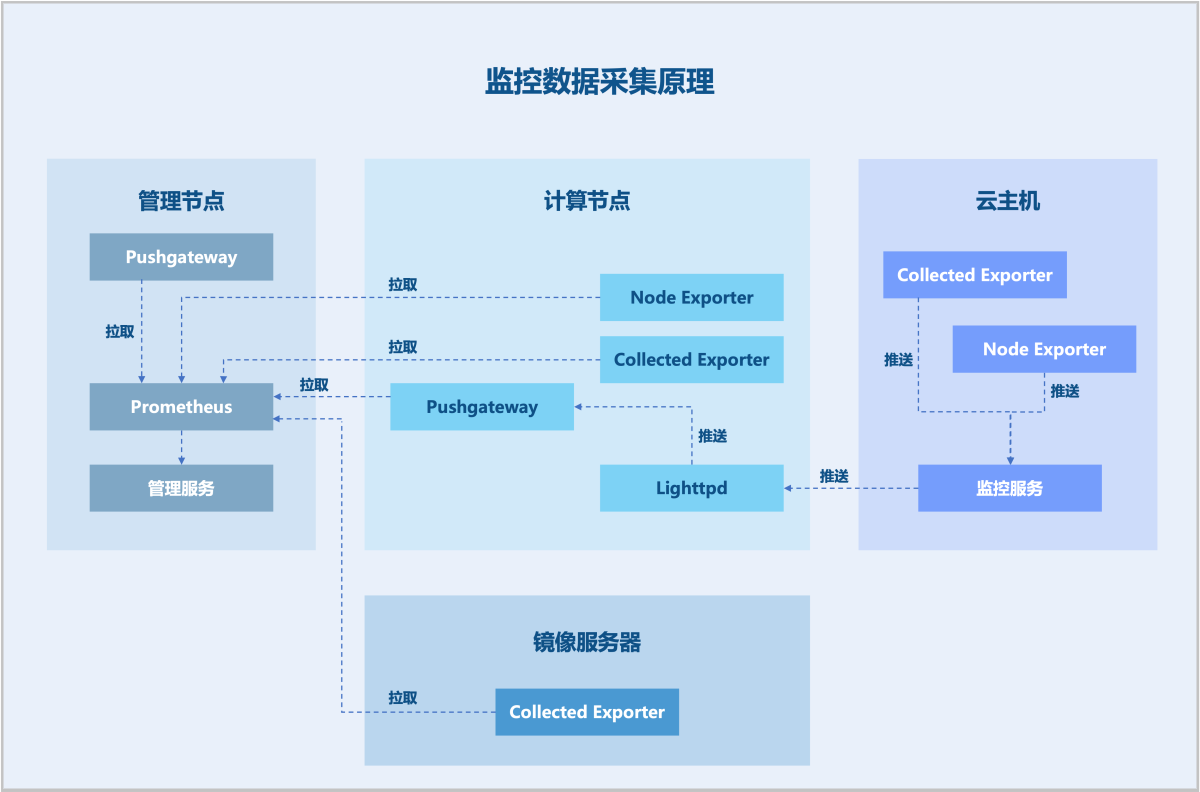
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
| groups:
- name: zwatch.rule
rules:
- record: ZStack:Host::ReclaimedMemoryInBytes
expr: clamp_min(sum(collectd_virt_memory{hostUuid!="", type="max_balloon"}) by (hostUuid) - on(hostUuid) sum(collectd_virt_memory{hostUuid!="", type="actual_balloon"}) by (hostUuid), 0)
- record: ZStack:Host::DiskCapacityInBytes
expr: node_filesystem_avail{hostUuid!="", fstype!~"proc|tmpfs|rootfs|ramfs|iso9660|rpc_pipefs", mountpoint!~"/tmp/zs-.*"}
- record: ZStack:Host::DiskAllReadBytes
expr: sum(irate(collectd_disk_disk_octets_0{hostUuid!=""}[10m])) by(hostUuid)
- record: ZStack:Host::CPUAverageWaitUtilization
expr: avg((sum(collectd_cpu_percent{type="wait", hostUuid!=""}) by(hostUuid) / sum(collectd_cpu_percent{hostUuid!=""}) by(hostUuid)) * 100) by (hostUuid)
- record: ZStack:Host::DiskAllWriteOps
expr: sum(irate(collectd_disk_disk_ops_1{hostUuid!=""}[10m])) by(hostUuid)
- record: ZStack:Host::NetworkAllOutBytesByServiceType
expr: sum(irate(host_network_all_out_bytes_by_service_type{hostUuid!=""}[10m])) by(hostUuid, service_type)
- record: ZStack:Host::DiskFreeCapacityInPercent
expr: ((node_filesystem_avail{hostUuid!="", fstype!~"proc|tmpfs|rootfs|ramfs|iso9660|rpc_pipefs", mountpoint!~"/tmp/zs-.*"} + 1) / (node_filesystem_size{hostUuid!="", fstype!~"proc|tmpfs|rootfs|ramfs|iso9660|rpc_pipefs", mountpoint!~"/tmp/zs-.*"} + 1)) * 100
- record: ZStack:Host::CPUAverageUsedUtilization
# 需要安装collectd才能用 collectd_cpu_percent这个指标
# expr: avg((sum(100 - collectd_cpu_percent{type="idle", hostUuid!=""}) by(hostUuid) / sum(collectd_cpu_percent{hostUuid!=""}) by(hostUuid)) * 100) by (hostUuid)
# 这里采用node_exporter采集的指标
expr: avg by(hostUuid) ((sum by(hostUuid, cpu) (node_cpu_seconds_total{mode!="idle", hostUuid!=""})/sum by(hostUuid, cpu) (node_cpu_seconds_total{hostUuid!=""})) * 100)
- record: ZStack:Host::DiskRootUsedCapacityInBytes
expr: sum(node_filesystem_size{hostUuid!="", fstype!="rootfs",mountpoint="/"} - node_filesystem_avail{hostUuid!="", fstype!="rootfs",mountpoint="/"}) by(hostUuid)
- record: ZStack:Host::NetworkOutPackets
expr: irate(collectd_interface_if_packets_1{hostUuid!=""}[10m])
- record: ZStack:Host::NetworkOutDropped
expr: irate(collectd_interface_if_dropped_1{hostUuid!=""}[10m])
- record: ZStack:Host::DiskWriteBytesWwid
expr: irate(collectd_disk_disk_octets_1[10m:]) * on (disk, hostUuid) group_left(wwid) node_disk_wwid
- record: ZStack:Host::CPUAllIdleUtilization
expr: (sum(collectd_cpu_percent{type="idle", hostUuid!=""}) by(hostUuid) / sum(collectd_cpu_percent{hostUuid!=""}) by(hostUuid)) * 100
- record: ZStack:Host::NetworkAllInBytes
expr: sum(irate(host_network_all_in_bytes{hostUuid!=""}[10m])) by(hostUuid)
- record: ZStack:Host::NetworkInDropped
expr: irate(collectd_interface_if_dropped_0{hostUuid!=""}[10m])
- record: ZStack:Host::DiskUsedCapacityInPercent
expr: (((node_filesystem_size{hostUuid!="", fstype!~"proc|tmpfs|rootfs|ramfs|iso9660|rpc_pipefs", mountpoint!~"/tmp/zs-.*"} - node_filesystem_avail{hostUuid!="", fstype!~"proc|tmpfs|rootfs|ramfs|iso9660|rpc_pipefs", mountpoint!~"/tmp/zs-.*"}) + 1) / (node_filesystem_size{hostUuid!="", fstype!~"proc|tmpfs|rootfs|ramfs|iso9660|rpc_pipefs", mountpoint!~"/tmp/zs-.*"} + 1)) * 100
- record: ZStack:Host::DiskWriteBytes
expr: irate(collectd_disk_disk_octets_1{hostUuid!=""}[10m])
- record: ZStack:Host::DiskZStackUsedCapacityInPercent
expr: (sum(zstack_used_capacity_in_bytes) by(hostUuid) / sum(node_filesystem_size{hostUuid!="", fstype!~"proc|tmpfs|rootfs|ramfs|iso9660|rpc_pipefs", mountpoint!~"/tmp/zs-.*"}) by(hostUuid)) * 100
- record: ZStack:Host::NetworkInErrors
expr: irate(collectd_interface_if_errors_0{hostUuid!=""}[10m])
- record: ZStack:Host::DiskRootUsedCapacityInPercent
expr: (sum(node_filesystem_size{hostUuid!="", fstype!="rootfs",mountpoint="/"} - node_filesystem_avail{hostUuid!="", fstype!="rootfs",mountpoint="/"}) by(hostUuid) / sum(node_filesystem_size{hostUuid!="", fstype!="rootfs",mountpoint="/"}) by(hostUuid)) * 100
- record: ZStack:Host::NetworkAllInPackets
expr: sum(irate(host_network_all_in_packages{hostUuid!=""}[10m])) by(hostUuid)
- record: ZStack:Host::DiskAllUsedCapacityInBytes
expr: sum(node_filesystem_size{hostUuid!="", fstype!~"proc|tmpfs|rootfs|ramfs|iso9660|rpc_pipefs", mountpoint!~"/tmp/zs-.*"} - node_filesystem_avail{hostUuid!="", fstype!~"proc|tmpfs|rootfs|ramfs|iso9660|rpc_pipefs", mountpoint!~"/tmp/zs-.*"}) by(hostUuid)
- record: ZStack:Host::DiskWriteOps
expr: irate(collectd_disk_disk_ops_1{hostUuid!=""}[10m])
- record: ZStack:Host::NetworkAllOutBytes
expr: sum(irate(host_network_all_out_bytes{hostUuid!=""}[10m])) by(hostUuid)
- record: ZStack:Host::VolumeGroupUsedCapacityInPercent
expr: ((vg_size - vg_avail + 1) / (vg_size + 1)) * 100
- record: ZStack:Host::NetworkAllInErrors
expr: sum(irate(host_network_all_in_errors{hostUuid!=""}[10m])) by(hostUuid)
- record: ZStack:Host::NetworkAllInBytesByServiceType
expr: sum(irate(host_network_all_in_bytes_by_service_type{hostUuid!=""}[10m])) by(hostUuid, service_type)
- record: ZStack:Host::NetworkAllOutErrorsByServiceType
expr: sum(irate(host_network_all_out_errors_by_service_type{hostUuid!=""}[10m])) by(hostUuid, service_type)
- record: ZStack:Host::NetworkOutErrors
expr: irate(collectd_interface_if_errors_1{hostUuid!=""}[10m])
- record: ZStack:Host::NetworkAllInPacketsByServiceType
expr: sum(irate(host_network_all_in_packages_by_service_type{hostUuid!=""}[10m])) by(hostUuid, service_type)
- record: ZStack:Host::DiskTransUsedCapacityInBytes
expr: sum(node_filesystem_size{hostUuid!="", fstype!="rootfs"} - node_filesystem_avail{hostUuid!="", fstype!="rootfs"}) by(hostUuid) - sum(zstack_used_capacity_in_bytes) by(hostUuid)
- record: ZStack:Host::NetworkAllInErrorsByServiceType
expr: sum(irate(host_network_all_in_bytes_by_service_type{hostUuid!=""}[10m])) by(hostUuid, service_type)
- record: ZStack:Host::DiskUsedCapacityInBytes
expr: node_filesystem_size{hostUuid!="", fstype!~"proc|tmpfs|rootfs|ramfs|iso9660|rpc_pipefs", mountpoint!~"/tmp/zs-.*"} - node_filesystem_avail{hostUuid!="", fstype!~"proc|tmpfs|rootfs|ramfs|iso9660|rpc_pipefs", mountpoint!~"/tmp/zs-.*"}
- record: ZStack:Host::DiskReadOpsWwid
expr: irate(collectd_disk_disk_ops_0[10m:]) * on (disk, hostUuid) group_left(wwid) node_disk_wwid
- record: ZStack:Host::DiskLatencyWwid
expr: (delta(collectd_disk_disk_io_time_0[1m]) + delta(collectd_disk_disk_io_time_1[1m])+1) / (delta(collectd_disk_disk_ops_0[1m]) + delta(collectd_disk_disk_ops_1[1m])+1) * on (disk, hostUuid) group_left(wwid) node_disk_wwid
- record: ZStack:Host::CPUAllUsedUtilization
expr: clamp((sum(100 - collectd_cpu_percent{type="idle", hostUuid!=""}) by(hostUuid) / sum(collectd_cpu_percent{hostUuid!=""}) by(hostUuid)) * 100, 0, 100)
- record: ZStack:Host::DiskReadBytesWwid
expr: irate(collectd_disk_disk_octets_0[10m:]) * on (disk, hostUuid) group_left(wwid) node_disk_wwid
- record: ZStack:Host::CPUAverageIdleUtilization
expr: avg((sum(collectd_cpu_percent{type="idle", hostUuid!=""}) by(hostUuid) / sum(collectd_cpu_percent{hostUuid!=""}) by(hostUuid)) * 100) by (hostUuid)
- record: ZStack:Host::CPUAverageUserUtilization
expr: avg((sum(collectd_cpu_percent{type="user", hostUuid!=""}) by(hostUuid) / sum(collectd_cpu_percent{hostUuid!=""}) by(hostUuid)) * 100) by (hostUuid)
- record: ZStack:Host::MemoryUsedBytes
expr: node_memory_MemTotal_bytes-node_memory_MemAvailable_bytes
- record: ZStack:Host::MemoryFreeInPercent
expr: 100 * (node_memory_MemAvailable_bytes/node_memory_MemTotal_bytes)
- record: ZStack:Host::NetworkOutBytes
expr: irate(collectd_interface_if_octets_1{hostUuid!=""}[10m])
- record: ZStack:Host::NetworkAllOutPacketsByServiceType
expr: sum(irate(host_network_all_out_packages_by_service_type{hostUuid!=""}[10m])) by(hostUuid, service_type)
- record: ZStack:Host::DiskAllWriteBytes
expr: sum(irate(collectd_disk_disk_octets_1{hostUuid!=""}[10m])) by(hostUuid)
- record: ZStack:Host::DiskTotalCapacityInBytes
expr: sum(node_filesystem_size{hostUuid!="", fstype!~"proc|tmpfs|rootfs|ramfs|iso9660|rpc_pipefs", mountpoint!~"/tmp/zs-.*"}) by(hostUuid)
- record: ZStack:Host::MemoryUsedInPercent
expr: 100 * (1 - (node_memory_MemAvailable_bytes/node_memory_MemTotal_bytes))
- record: ZStack:Host::DiskLatency
expr: (delta(collectd_disk_disk_io_time_0[1m]) + delta(collectd_disk_disk_io_time_1[1m])+1) / (delta(collectd_disk_disk_ops_0[1m]) + delta(collectd_disk_disk_ops_1[1m])+1)
- record: ZStack:Host::DiskReadBytes
expr: irate(collectd_disk_disk_octets_0{hostUuid!=""}[10m])
- record: ZStack:Host::DiskWriteOpsWwid
expr: irate(collectd_disk_disk_ops_1[10m]) * on (disk, hostUuid) group_left(wwid) node_disk_wwid
- record: ZStack:Host::NetworkInPackets
expr: irate(collectd_interface_if_packets_0{hostUuid!=""}[10m])
- record: ZStack:Host::CPUUsedUtilization
expr: abs(100 - collectd_cpu_percent{type="idle", hostUuid!=""})
- record: ZStack:Host::DiskAllFreeCapacityInPercent
expr: (sum(node_filesystem_avail{hostUuid!="", fstype!~"proc|tmpfs|rootfs|ramfs|iso9660|rpc_pipefs", mountpoint!~"/tmp/zs-.*"}) by(hostUuid) / sum(node_filesystem_size{hostUuid!="", fstype!~"proc|tmpfs|rootfs|ramfs|iso9660|rpc_pipefs", mountpoint!~"/tmp/zs-.*"}) by(hostUuid)) * 100
- record: ZStack:Host::DiskTransUsedCapacityInPercent
expr: (sum(node_filesystem_size{hostUuid!="", fstype!="rootfs"} - node_filesystem_avail{hostUuid!="", fstype!="rootfs"}) by(hostUuid) - sum(zstack_used_capacity_in_bytes) by(hostUuid)) / sum(node_filesystem_size{hostUuid!="", fstype!="rootfs"}) by(hostUuid) * 100
- record: ZStack:Host::DiskAllReadOps
expr: sum(irate(collectd_disk_disk_ops_0{hostUuid!=""}[10m])) by(hostUuid)
- record: ZStack:Host::NetworkAllOutPackets
expr: sum(irate(host_network_all_out_packages{hostUuid!=""}[10m])) by(hostUuid)
- record: ZStack:Host::NetworkInBytes
expr: irate(collectd_interface_if_octets_0{hostUuid!=""}[10m])
- record: ZStack:Host::DiskReadOps
expr: irate(collectd_disk_disk_ops_0{hostUuid!=""}[10m])
- record: ZStack:Host::CPUAverageSystemUtilization
expr: avg((sum(collectd_cpu_percent{type="system", hostUuid!=""}) by(hostUuid) / sum(collectd_cpu_percent{hostUuid!=""}) by(hostUuid)) * 100) by (hostUuid)
- record: ZStack:Host::DiskAllUsedCapacityInPercent
expr: (sum(node_filesystem_size{hostUuid!="", fstype!~"proc|tmpfs|rootfs|ramfs|iso9660|rpc_pipefs", mountpoint!~"/tmp/zs-.*"} - node_filesystem_avail{hostUuid!="", fstype!~"proc|tmpfs|rootfs|ramfs|iso9660|rpc_pipefs", mountpoint!~"/tmp/zs-.*"}) by(hostUuid) / sum(node_filesystem_size{hostUuid!="", fstype!~"proc|tmpfs|rootfs|ramfs|iso9660|rpc_pipefs", mountpoint!~"/tmp/zs-.*"}) by(hostUuid)) * 100
- record: ZStack:Host::DiskAllFreeCapacityInBytes
expr: sum(node_filesystem_avail{hostUuid!="", fstype!~"proc|tmpfs|rootfs|ramfs|iso9660|rpc_pipefs", mountpoint!~"/tmp/zs-.*"}) by(hostUuid)
- record: ZStack:Host::NetworkAllOutErrors
expr: sum(irate(host_network_all_out_errors{hostUuid!=""}[10m])) by(hostUuid)
|