在docker部署多个微服务后,发现宿主机内存不断的慢慢上涨,因此想知道是哪个微服务慢慢不断让内存上涨,因此想用一个监控软件,监控所有微服务的性能等指标
名词介绍
prometheus+cadvisor简单的性能指标采集展示框架
资源占用
- cadvisor:112M左右
- Prometheus:300M+(随时间流逝内存在上升)
docker swarm模式部署
官方部署文档
prometheus的配置文件/docker_data/v-monitor/prometheus/prometheus.yml内容如下:
1
2
3
4
5
6
| scrape_configs:
- job_name: cadvisor
scrape_interval: 5s
static_configs:
- targets:
- cadvisor:8080
|
Swarm部署脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| version: '3.2'
services:
prometheus:
image: prom/prometheus:latest
container_name: prometheus
ports:
- 9090:9090
command:
- --config.file=/etc/prometheus/prometheus.yml
volumes:
- /docker_data/v-monitor/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml:ro
depends_on:
- cadvisor
cadvisor:
image: google/cadvisor:latest
container_name: cadvisor
ports:
- 8080:8080
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
|
| 指标名称 |
类型 |
含义 |
| container_memory_usage_bytes |
gauge |
容器当前的内存使用量(单位:字节) |
| machine_memory_bytes |
gauge |
宿主机内存总量(单位:字节) |
内存图表展示
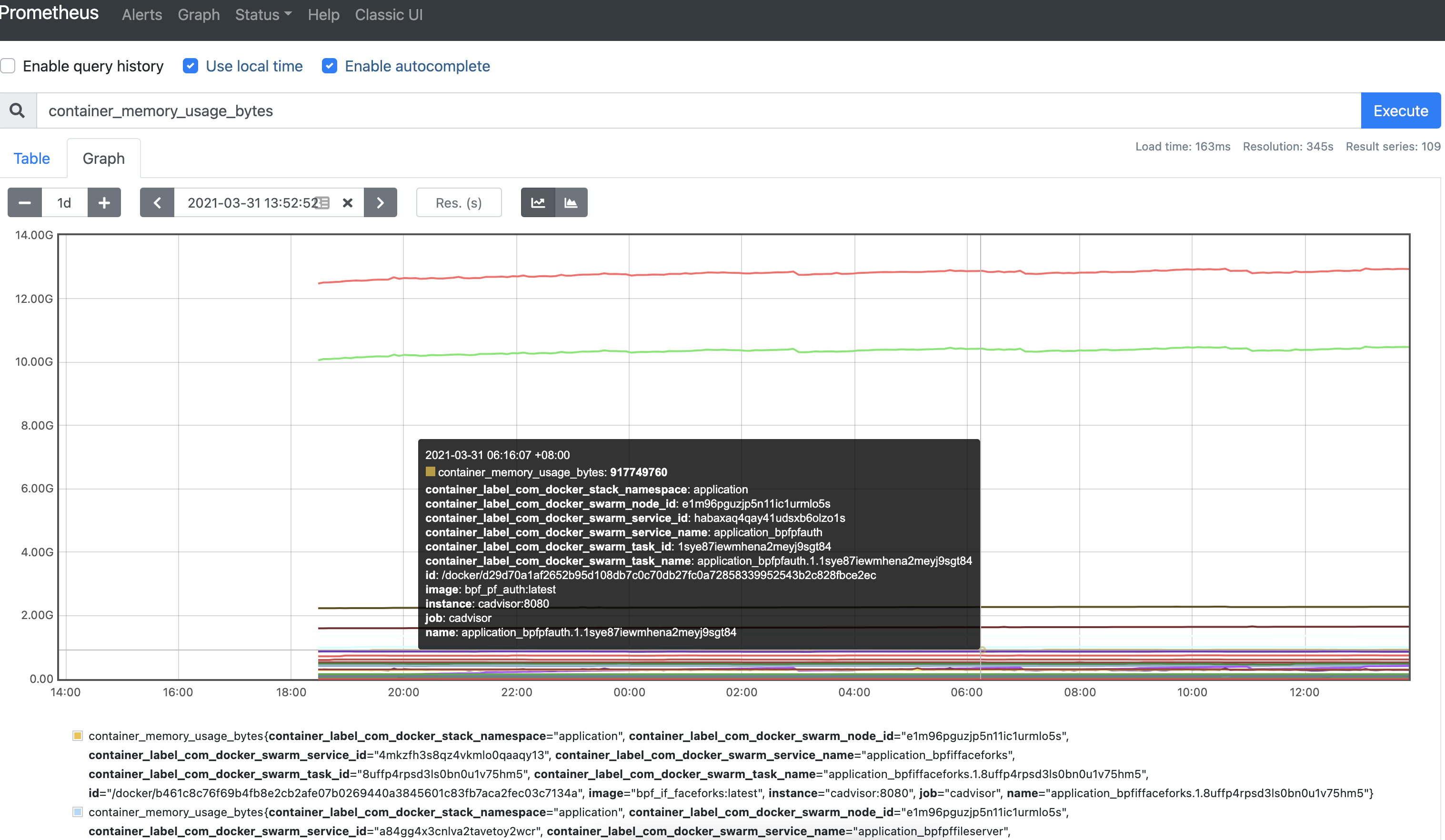
增加Grafana仪表板显示prometheus
增加Grafana部署
1
2
3
4
5
| grafana:
image: grafana/grafana:latest
container_name: grafana
ports:
- 3000:3000
|
默认账号和密码是admin/admin
官方配置手册GRAFANA SUPPORT FOR PROMETHEUS
- 添加数据源:点击configuration->data sources->prometheus->在url输入pro服务的地址(http://prometheus:9090)
- 寻找合适的dashboard:去grafana dashboard找一个适合自己的模版(我这里用Docker and system monitoring的模版id为893)
- 添加dashboard:点击dashboard->import->输入id添加模版(893)
增加部署
1
2
3
4
5
6
7
8
9
10
11
12
| node-exporter:
image: prom/node-exporter:latest
command:
- '--path.rootfs=/host'
pid: host
volumes:
- '/:/host:ro,rslave'
ports:
- target: 9100
published: 9100
protocol: tcp
mode: host
|
修改配置prometheus.yml内容如下:
1
2
3
4
5
| scrape_configs:
- job_name: 'cadvisor'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090','cadvisor:8080','node-exporter:9100']
|
中文文档
1
2
|
node_filesystem_free_bytes{fstype="rootfs"}[1m]
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
sum(container_memory_rss{container_label_com_docker_swarm_service_name=~".+"}) by (container_label_com_docker_swarm_service_name)
sum(container_memory_rss{name=~".+"})by(image)
sum(label_replace(container_memory_rss{name=~".+"},"image_sub","$1","image", "(.*)(:)(.*)"))by(image_sub)
label_replace(container_memory_rss{name=~".+"},"name","$1","name", "(.*)(\\.1\\.)(.*)")
sum(label_replace(container_memory_rss{name=~".+"},"name","$1","name", "(.*)(\\.1\\.)(.*)"))by(name)
sum(label_replace(rate(container_cpu_usage_seconds_total{name=~".+"}[$interval]),"name","$1","name", "(.*)(\\.1\\.)(.*)"))by (name) * 100
|
cadvisor+influxDB+Grafana
待更新…
参考
容器监控:cAdvisor
常见问题
- 图表不显示数据,显示N/A,检查里面的查询语句,是否表改了名字,新版本好多表都加了
_bytes后缀,找到升级后的表名替换旧的就可以了
- 更新表的字段后显示
Only queries that return single series/table is supported错误,检查右边的panel是否需要合并,不需要合并应该会选中一个图表类型
附录
完整的swarm部署文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| version: '3.2'
services:
prometheus:
image: prom/prometheus:latest
ports:
- 14003:9090
command:
- --config.file=/etc/prometheus/prometheus.yml
volumes:
- /docker_data/v-monitor/prometheus/config:/etc/prometheus
- /docker_data/v-monitor/prometheus/data:/prometheus
cadvisor:
image: google/cadvisor:latest
ports:
- 14004:8080
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
grafana:
image: grafana/grafana:latest
ports:
- 14002:3000
volumes:
- /docker_data/v-monitor/grafana:/var/lib/grafana
node-exporter:
image: prom/node-exporter:latest
command:
- '--path.rootfs=/host'
pid: host
volumes:
- '/:/host:ro,rslave'
ports:
- target: 9100
published: 9100
protocol: tcp
mode: host
|
prometheus.yml
1
2
3
4
5
| scrape_configs:
- job_name: 'cadvisor'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090','cadvisor:8080','node-exporter:9100']
|